遵義市生態(tài)漁業(yè)技術(shù)服務(wù)團(tuán)深入湄潭縣,開展農(nóng)技人員創(chuàng)新創(chuàng)業(yè)“揭榜掛帥”及基礎(chǔ)示范服務(wù)工作,旨在推動(dòng)當(dāng)?shù)厣鷳B(tài)漁業(yè)高質(zhì)量發(fā)展,同時(shí)帶動(dòng)畜牧漁業(yè)飼料銷售產(chǎn)業(yè)的協(xié)同進(jìn)步。
在“揭榜掛帥”活動(dòng)中,服務(wù)團(tuán)聚焦湄潭縣生態(tài)漁業(yè)的關(guān)鍵技術(shù)難題,如水質(zhì)調(diào)控、病害防治和品種優(yōu)化等,通過公開征集需求、發(fā)布榜單,鼓勵(lì)農(nóng)技人員主動(dòng)“揭榜”攻關(guān)。這不僅激發(fā)了基層技術(shù)人員的創(chuàng)新活力,還促進(jìn)了科研成果的快速轉(zhuǎn)化應(yīng)用,為漁業(yè)可持續(xù)發(fā)展注入了新動(dòng)力。服務(wù)團(tuán)還深入養(yǎng)殖基地,開展現(xiàn)場(chǎng)指導(dǎo)和培訓(xùn),提升從業(yè)人員的專業(yè)技能。
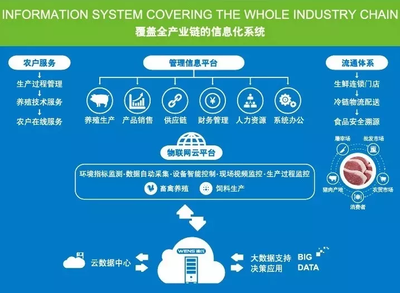
在基礎(chǔ)示范服務(wù)方面,服務(wù)團(tuán)建立了多個(gè)生態(tài)漁業(yè)示范點(diǎn),推廣綠色養(yǎng)殖模式和先進(jìn)技術(shù),如循環(huán)水養(yǎng)殖和生態(tài)混養(yǎng),以降低環(huán)境污染、提高養(yǎng)殖效益。通過實(shí)地示范,農(nóng)戶直觀學(xué)習(xí)了科學(xué)管理方法,增強(qiáng)了應(yīng)用新技術(shù)的信心。服務(wù)團(tuán)還結(jié)合畜牧漁業(yè)飼料銷售,推薦優(yōu)質(zhì)環(huán)保飼料產(chǎn)品,幫助養(yǎng)殖戶優(yōu)化飼料配方,降低養(yǎng)殖成本,提升產(chǎn)品品質(zhì),形成了“技術(shù)+銷售”一體化服務(wù)鏈條。
此次活動(dòng)不僅強(qiáng)化了湄潭縣的漁業(yè)技術(shù)支撐,還促進(jìn)了畜牧漁業(yè)飼料銷售的市場(chǎng)拓展,為區(qū)域農(nóng)業(yè)現(xiàn)代化和鄉(xiāng)村振興提供了有力保障。服務(wù)團(tuán)將繼續(xù)深化此類服務(wù),推動(dòng)更多創(chuàng)新成果落地生根。